Apache Spark. Apache Spark is a general-purpose graph execution engine that allows users to analyze large data sets with very high performance. One common use case for Spark is executing streaming analytics. In addition, Spark brings ease of development to distributed processing..
Correspondingly, how does spark execution work?
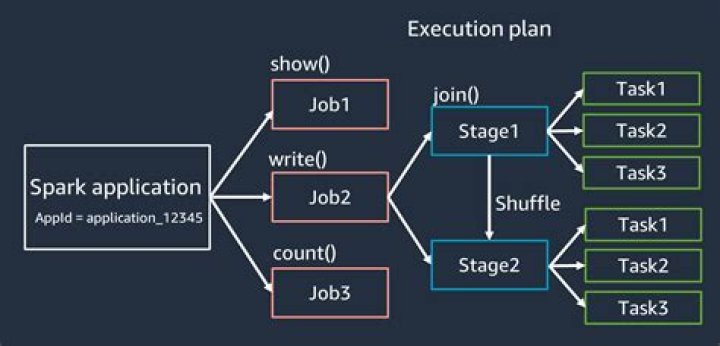
The Spark driver is responsible for converting a user program into units of physical execution called tasks. At a high level, all Spark programs follow the same structure. They create RDDs from some input, derive new RDDs from those using transformations, and perform actions to collect or save data.
Beside above, what is spark processing? Spark is a general-purpose distributed data processing engine that is suitable for use in a wide range of circumstances. On top of the Spark core data processing engine, there are libraries for SQL, machine learning, graph computation, and stream processing, which can be used together in an application.
One may also ask, what is Spark used for?
Apache Spark is open source, general-purpose distributed computing engine used for processing and analyzing a large amount of data. Just like Hadoop MapReduce, it also works with the system to distribute data across the cluster and process the data in parallel.
What is Apache spark engine?
Apache Spark is a powerful unified analytics engine for large-scale distributed data processing and machine learning. On top of the Spark core data processing engine are libraries for SQL, machine learning, graph computation, and stream processing.
Related Question Answers
What happens after spark submit?
What happens when a Spark Job is submitted? When a client submits a spark user application code, the driver implicitly converts the code containing transformations and actions into a logical directed acyclic graph (DAG). The cluster manager then launches executors on the worker nodes on behalf of the driver.What is Dag spark?
(Directed Acyclic Graph) DAG in Apache Spark is a set of Vertices and Edges, where vertices represent the RDDs and the edges represent the Operation to be applied on RDD. In Spark DAG, every edge directs from earlier to later in the sequence.How do I tune a spark job?
The following sections describe common Spark job optimizations and recommendations. - Choose the data abstraction.
- Use optimal data format.
- Select default storage.
- Use the cache.
- Use memory efficiently.
- Optimize data serialization.
- Use bucketing.
- Optimize joins and shuffles.
How do I start a spark cluster?
Setup an Apache Spark Cluster - Navigate to Spark Configuration Directory. Go to SPARK_HOME/conf/ directory.
- Edit the file spark-env.sh – Set SPARK_MASTER_HOST. Note : If spark-env.sh is not present, spark-env.sh.template would be present.
- Start spark as master. Goto SPARK_HOME/sbin and execute the following command.
- Verify the log file.
How is Dag created in spark?
Creation of DAG in Spark When an action is called on Spark RDD at a high level, DAG is created and is submitted to the DAG scheduler. Operators are divided into stages of the task in the DAG scheduler. A stage contains task based on the partition of the input data. The DAG scheduler pipelines operators together.How spark decides number of tasks?
- Task: represents a unit of work on a partition of a distributed dataset. So in each stage, number-of-tasks = number-of-partitions, or as you said "one task per stage per partition”.
- Each vcore can execute exactly one task at a time.
What happens when an action is executed?
Every action represents a job in the spark. This job get executed by action. Spark reads all the instruction/transformations that are been provided in the job. These transformations get parsed and converted in the execution plan (logical plan).Is spark a programming language?
SPARK is a formally defined computer programming language based on the Ada programming language, intended for the development of high integrity software used in systems where predictable and highly reliable operation is essential. SPARK 2014 is a complete re-design of the language and supporting verification tools.Does Google use spark?
Google previewed its Cloud Dataflow service, which is used for real-time batch and stream processing and competes with homegrown clusters running the Apache Spark in-memory system, back in June 2014, put it into beta in April 2015, and made it generally available in August 2015.Is Apache spark a programming language?
Apache Spark enhances the speed and supports multiple programming languages such as - Scala, Python, Java and R. All these 4 APIs possess their own special features and are predominant for programming in Spark. Choosing a programming language for Apache Spark depends on the type of application to be developed.What is the spark?
What is the spark? It's that certain something you feel when you meet someone and there is a recognizable mutual attraction. You want to rip off his or her clothes, and undress his or her mind. It's a magnetic pull between two people where you both feel mentally, emotionally, physically and energetically connected.What exactly is spark?
Apache Spark. Spark is a distributed platform for executing complex multi-stage applications, like machine learning algorithms, and interactive ad hoc queries. Spark provides an efficient abstraction for in-memory cluster computing called Resilient Distributed Dataset.Why do we need RDD in spark?
Resilient Distributed Datasets (RDD) is a fundamental data structure of Spark. It is an immutable distributed collection of objects. Spark makes use of the concept of RDD to achieve faster and efficient MapReduce operations. Let us first discuss how MapReduce operations take place and why they are not so efficient.Is spark open source?
Apache Spark is an open-source distributed general-purpose cluster-computing framework. Originally developed at the University of California, Berkeley's AMPLab, the Spark codebase was later donated to the Apache Software Foundation, which has maintained it since.What is spark in relationship?
Most relationships start with a spark. What's a spark, you ask? Well, it's that instant magnetic chemistry you and another person feel toward each other. A spark is that instant magnetic chemistry you and another person feel toward each other.What is difference between Hadoop and Spark?
In fact, the key difference between Hadoop MapReduce and Spark lies in the approach to processing: Spark can do it in-memory, while Hadoop MapReduce has to read from and write to a disk. As a result, the speed of processing differs significantly – Spark may be up to 100 times faster.Is spark a framework?
Apache Spark is a Framework and RDD is key abstraction of Spark. However, on defining: In simple terms, a platform for developing software applications is what we call a framework, or software framework. It offers a foundation on which software developers can build programs for a specific platform.What is the difference between Scala and Spark?
The main difference between Spark and Scala is that the Apache Spark is a cluster computing framework designed for fast Hadoop computation while the Scala is a general-purpose programming language that supports functional and object-oriented programming. On the other hand, Scala is a programming language.Which is better Hadoop or spark?
Spark is 100 times faster than Hadoop MapReduce. MapReduce can process data in batch mode. Apache Spark is a lightning fast cluster computing tool. Spark runs applications in Hadoop clusters up to 100x faster in memory and 10x faster on disk.